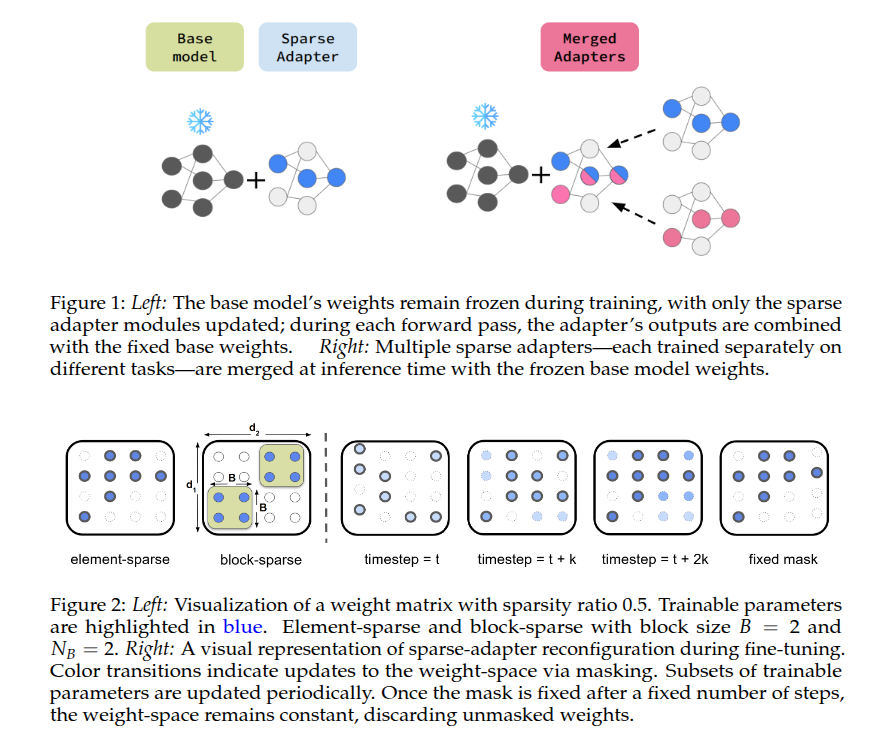
Model merging aims to integrate knowledge from multiple task experts into a single, unified multi-task model. Parameter-efficient adaptation, namely LoRA, have become the de-facto approach to obtain memory-friendly task experts. In this paper, we study the properties of sparse adapters, which train only a subset of weights in the base neural network, as potential adaptation recipe for downstream model merging. First, we propose a simple method for training highly effective sparse adapters, which surprisingly outperforms both LoRA and full fine-tuning in our setting. Next, we investigate the merging properties of these sparse adapters, merging up to 20 natural language processing task adapters. Our findings demonstrate that sparse adapters yield superior in-distribution performance post-merging compared to LoRA or full model merging. Achieving strong held-out performance remains a challenge for all methods considered.
@inproceedings{
arnob2025exploring,
title={Exploring Sparse Adapters for Scalable Merging of Parameter Efficient Experts},
author={Samin Yeasar Arnob and Zhan Su and Minseon Kim and Oleksiy Ostapenko and Riyasat Ohib and Esra'a Saleh and Doina Precup and Lucas Caccia and Alessandro Sordoni},
booktitle={Second Conference on Language Modeling},
year={2025},
url={https://openreview.net/forum?id=te7UC87Zbw}
}
